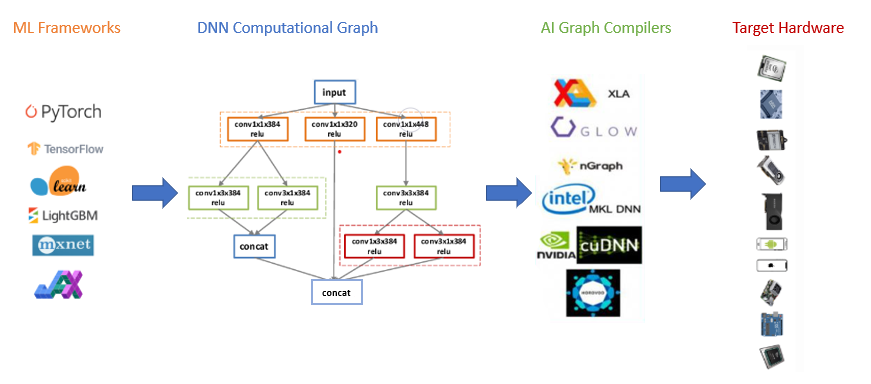
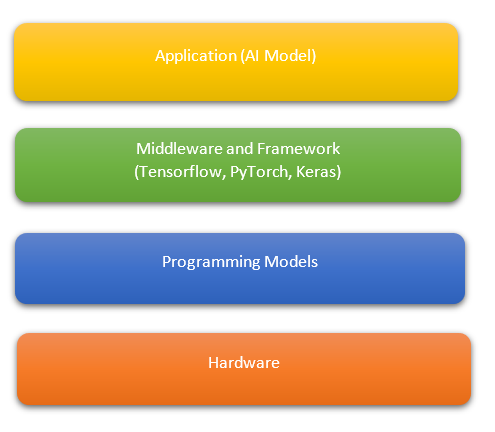
What are AI accelerators?
Published:
AI Accelerators Introduction

AI accelerator is a specialized hardware accelerator designed to accelerate Machine Learning and Artificial Intelligence applications, including neural networks and machine vision.
The datacenter chips that are running the Machine learning and Deep learning workloads, consist of a couple of CPU cores and the AI accelerators that are connected to these host CPUs and together as a system thy are supposed to work very efficiently either training a model or for high capacity inference.
CPU, GPU - Comparative study
Before comparing CPUs and GPUs, it is important to understand the design philosophy behind each architecture. Both processors execute instructions and perform computations, but they are optimized for different objectives. CPUs are designed to minimize latency and maximize single-thread performance, whereas GPUs are designed to maximize throughput by executing many operations in parallel.
CPU Architecture
A CPU is a general-purpose processor optimized for executing a wide variety of workloads efficiently. Modern CPUs contain a relatively small number of powerful cores, each capable of executing instructions independently.
To improve performance, CPU cores incorporate sophisticated hardware features such as:
- Deep cache hierarchies (L1, L2, L3 caches)
- Branch prediction
- Speculative execution
- Out-of-order execution
- Register renaming
- SIMD vector units (AVX, AVX-512, SVE, etc.)
These features allow CPUs to efficiently execute workloads with:
- Complex control flow
- Frequent branching
- Irregular memory accesses
- Sequential dependencies
A server CPU typically contains tens of cores running at relatively high clock frequencies. SIMD instructions allow each core to perform operations on multiple data elements simultaneously, improving data-parallel performance while maintaining strong single-thread execution capability.
The primary goal of a CPU is to reduce the execution latency of a single task.
GPU Architecture
A GPU is a throughput-oriented processor optimized for executing massive numbers of parallel operations. Instead of dedicating a large portion of the chip to control logic and caching, GPUs allocate significantly more silicon area to arithmetic execution units.
A modern GPU contains:
- Many Streaming Multiprocessors (SMs)
- Thousands of arithmetic units (CUDA Cores)
- Tensor Cores for matrix operations
- Large register files
- High-bandwidth memory interfaces
- Hardware thread schedulers
Rather than executing a few threads extremely quickly, a GPU executes thousands of threads concurrently.
SIMT Execution Model
GPUs use the SIMT (Single Instruction, Multiple Threads) execution model.
In NVIDIA GPUs, threads are organized as:
Thread
↓
Warp (32 threads)
↓
Thread Block
↓
Grid
The fundamental scheduling unit is a warp, which consists of 32 threads.
For example:
C[i] = A[i] + B[i];
A single warp may execute:
Thread 0 computes C[0]
Thread 1 computes C[1]
Thread 2 computes C[2]
...
Thread 31 computes C[31]
All 32 threads execute the same instruction simultaneously on different data elements.
This is conceptually similar to SIMD but provides a more flexible programming model because each thread maintains its own:
- Program counter
- Registers
- Thread-local state
Latency Hiding
One of the most important concepts in GPU architecture is latency hiding.
A CPU attempts to reduce latency through mechanisms such as:
- Large caches
- Speculation
- Out-of-order execution
A GPU takes a different approach.
Suppose a warp issues a memory load that takes 500 cycles.
Instead of waiting:
Warp A → Memory Load → Stall
the GPU scheduler switches to another ready warp:
Warp A → Waiting
Warp B → Execute
Warp C → Execute
Warp D → Execute
When Warp A’s memory request completes, execution resumes.
Modern GPUs maintain thousands of resident threads specifically to hide memory latency.
This strategy is often referred to as:
Throughput-oriented execution rather than latency-oriented execution.
Memory Hierarchy
GPUs have a different memory hierarchy from CPUs.
CPU Memory Hierarchy
Registers
↓
L1 Cache
↓
L2 Cache
↓
L3 Cache
↓
DRAM
CPU caches are designed to minimize latency.
GPU Memory Hierarchy
Registers
↓
Shared Memory / L1 Cache
↓
L2 Cache
↓
HBM or GDDR Memory
Key characteristics:
- Much higher memory bandwidth
- Higher memory latency
- Smaller cache capacity per thread
- Programmer-visible shared memory
For example:
| Device | Memory Bandwidth |
|---|---|
| Server CPU | ~200–500 GB/s |
| Modern GPU | ~3–8 TB/s |
This enormous bandwidth is critical for workloads such as:
- Deep learning
- Matrix multiplication
- Scientific computing
- Graphics rendering
Occupancy and Resource Utilization
GPU performance depends heavily on occupancy.
Occupancy refers to:
The number of active warps resident on an SM relative to the hardware maximum.
Occupancy is limited by:
- Registers per thread
- Shared memory usage
- Block size
- Hardware limits
For example:
SM supports 64 warps
Application launches 32 warps
Occupancy = 50%
Higher occupancy generally improves latency hiding, although maximum occupancy does not always produce maximum performance.
Tensor Cores
Modern NVIDIA GPUs contain specialized Tensor Cores.
Tensor Cores accelerate matrix operations such as:
D = A × B + C
which form the basis of:
- Transformers
- LLMs
- CNNs
- Scientific simulations
Tensor Cores can deliver orders-of-magnitude higher throughput than traditional CUDA Cores for matrix-heavy workloads.
Examples include:
- FP16 matrix multiplication
- BF16 matrix multiplication
- FP8 matrix multiplication
- INT8 inference
Modern LLM training performance is heavily dependent on Tensor Core utilization.
CPU vs GPU Design Tradeoffs
| Feature | CPU | GPU |
|---|---|---|
| Primary Goal | Low Latency | High Throughput |
| Core Count | Tens | Thousands of Execution Units |
| Clock Frequency | Higher | Lower |
| Cache Size | Large | Smaller per Thread |
| Branch Handling | Excellent | Less Efficient |
| Memory Bandwidth | Moderate | Extremely High |
| Thread Count | Hundreds | Tens of Thousands |
| Scheduling | Complex Out-of-Order Execution | Massive Hardware Multithreading |
| Best For | Databases, OS, Web Servers, Compilers | AI, HPC, Graphics, Simulations |
Why GPUs Excel at LLM Training
LLM training consists primarily of:
- Matrix multiplications (GEMMs)
- Attention computations
- Tensor operations
- Gradient calculations
These operations are:
- Highly parallel
- Regular
- Compute-intensive
GPUs are specifically designed for this workload:
- Tensor Cores accelerate GEMMs.
- Thousands of threads process tensors in parallel.
- Massive memory bandwidth feeds the compute units.
- Hardware schedulers hide memory latency.
- High-speed interconnects such as NVLink enable multi-GPU scaling.
As a result, modern large language models are trained on clusters containing thousands of GPUs rather than CPUs.
Why AI Accelerators?
Now that we have established the core concepts of CPUs and GPUs, let’s talk about the need of AI accelerators. Dedicated AI processors have a large dedicated compute to general-compute ratio. They are ideal for workloads with predictable memory access patterns, as they can provide the highest performance per power when the data is properly pipelined to compute. GPUs originally architecture for graphics but because of parallelism that they have, they are pretty efficient to compare to using just CPUs.
Since GPU is already an efficient machine for model training, what does AI accelerators do better? In neural networks, It’s either matrix-matrix multiplication or matrix-vector multiplication that needs to be done very efficiently. Hence, a matmul engine which is very efficient and a cluster of tensor processor cores with custom instruction set and AI centric operations boosts the performance overall. The combination of fully programmable tensor-cores and a very efficient matmul engine allows us to get to really high efficiency in terms of computing and memory resources.
Which hardware is best for neural networks?
While there are multiple different types of processors, they are becoming more heterogeneous and are actually beginning to share more common characteristics. Given the growing complexity of neural networks, the right processor is one that balances general purpose compute and specialized compute and scales well across nodes. In general, if you are working with variety of complex workloads or a starting point when exploring an AI solution, a more general purpose CPU processor especially one with built-in acceleration is likely the best choice.
If you require the highest performance per power with predictable memory access patterns, or you require something more specialized then a dedicated accelerator can likely be the best choice. And a vital consideration is that the processor is simple to program and to use.