What are Graph Compilers? (LLVM, MLIR)
Published:
Graph compilers Introduction
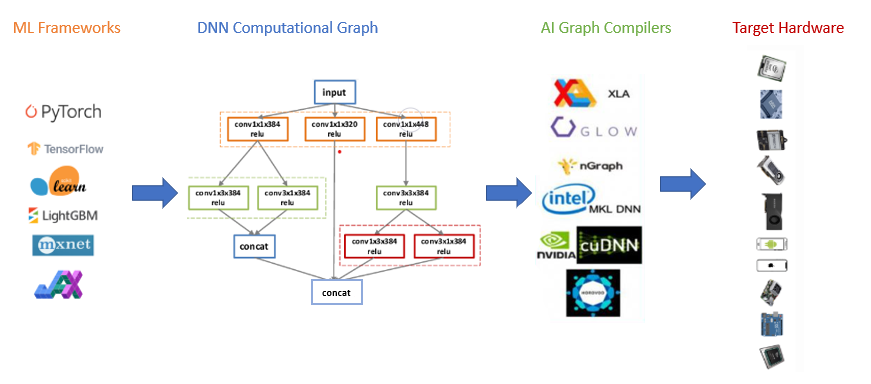
With the increase in popularity of Artificial Intelligence applications many machine learning and deep learning frameworks have been developed to create ML/DL models e.g. Tensorflow, PyTorch, Keras, mxNet.With dataflow at the heart of most of these computations, efforts have been made to improve performance through graph compilation techniques. AI training is computationally intensive and High Performance Computing has been a key driver in AI growth. AI training deployments in HPC or cloud can be optimised with target-specific libraries, graph compilers, and by improving data movement or IO.
Graph compilers aim to optimise the execution of a DNN graph by generating an optimised code for target hardware thus accelerating the training and deployment of DL models. The Deep learning models are usually represented as computational graphs, with nodes representing tensor operators, and edges the data dependencies between them. This computational graph is then used to further optimise for different hardware back-ends which include operator fusion, memory latency hiding, etc.
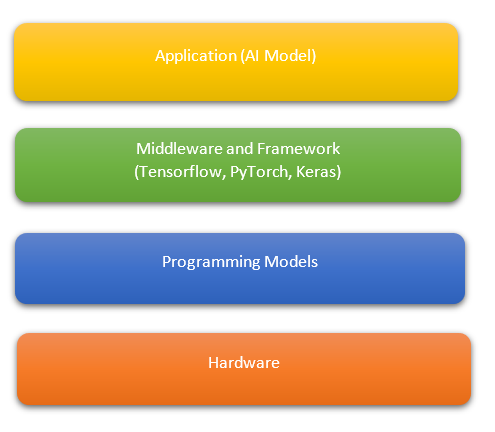
With the increase in ML/DL frameworks and also increase in hardware optimised for different ML use cases, e.g. GPU, TPU, AI accelerators, question arises how do we make a model built with an arbitrary framework run on arbitrary hardware?

Providing support for a framework on a type of hardware is tedious, time-consuming and engineering intensive. A fundamental challenge is that different hardware types have different compute primitives and different memory layouts. Deploying ML models to new hardware such as mobile phone, FPGAs, embedded devices, GPUs, etc. requires mutual effort. some examples of graph compilers are:
- NVIDIA TensorRT : This compiler is built on top of CUDA and optimises the inference by providing high throughput and low latency for deep learning inference applications. It supports ONNX, thus by extension supporting models trained by different frameworks, it provides optimisations based on reduced precision and hence provide faster performance compared to CPU-only platforms during inference.
- Intel nGraph : It is an end-to-end compiler for training and inference, it supports TensorFlow, MXNet, ONNX, etc. It can deliver increased normalized inference throughput leveraging MKL-DNN on Intel Xeon Scalable processor.
- GLOW: It optimises Neural Networks by lowering the graph to two intermediate representations. Glow works with PyTorch and supports multiple operators and targets. Glow can consume ONNX (open standard for serializing AI model) as an input and thus can support other frameworks.
- XLA : This compiler accelerates linear algebra computations in TensorFlow models and achieves a 1.15x speedup when enabled on standard benchmarks.
Intermediate Representation
For every new hardware type and device, instead of targeting a new compiler and libraries, we can create a generic representation which bridge frameworks and platforms. Framework developers will no longer have to support every type of hardware and only need to translate the framework code to Intermediate Representation and hardware engineers can support this IR after optimizations for respective hardware. IR lies at the core of how these compilers works, the original code of the model is converted into series of high and low level Intermediate Representations before generating hardware-native code to run your models on a certain platform.
Following are the commonly used intermediate code representations:
- Postfix Notation: Also known as reverse Polish notation or suffix notation. The postfix notation places the operator at the right end, e.g infix expr: a + b is represented in postfix notation as: ab+, hence the operator follows the operand.
- Three Address Code: A statement involving no more than three references(two for operands and one for result) is known as a three address statement. A sequence of three address code statements is known as three address code. There are three ways to represent Three-Address Code: Quadruples, Triples, Indirect Triples.
- Syntax Tree: It is condensed form of a parse tree. The operator and keyword nodes of the parse tree are moved to their parents and a chain of single productions is replaced by the single link in the syntax tree the internal nodes are operators and child nodes are operands.
High level IRs are generally hardware-agnostic(doesn’t care what hardware they’ll be running), while low-level IRs are framework-agnostic(doesn’t care what framework the model was build with). To generate machine-native code from an IR, compilers typically leverage a code generator, the most popular codegen used by ML compilers is LLVM. XLA, NVIDIA CUDA Compiler (NVCC), TVM, MLIR all use LLVM.
LLVM - Low Level Virtual Machine
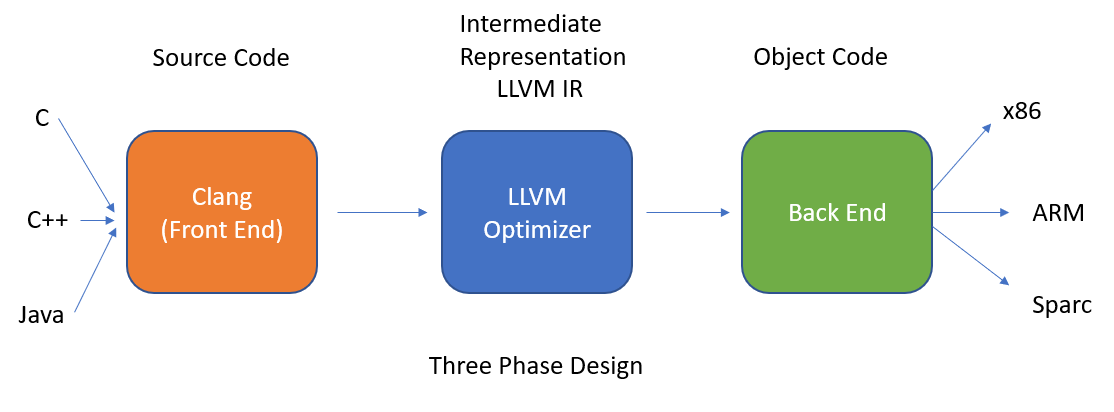
The LLVM package contains a collection of modular and reusable compiler and toolchain technologies. The Low Level Virtual Machine (LLVM) Core libraries provide a modern source and target-independent optimizer, along with code generation support for many popular CPUs (as well as some less common ones!). These libraries are built around a well specified code representation known as the LLVM intermediate representation (“LLVM IR”).
A developer generates instructions in intermediate representation, or IR. LLVM can then compile the IR into a standalone binary or perform a JIT (just-in-time) compilation on the code to run in the context of another program, such as an interpreter or runtime for the language. LLVM’s APIs provide primitives for developing many common structures and patterns found in programming languages. LLVM doesn’t just compile the IR to native machine code. You can also programmatically direct it to optimize the code with a high degree of granularity, all the way through the linking process. The optimizations can be quite aggressive, including things like inlining functions, eliminating dead code (including unused type declarations and function arguments), and unrolling loops.
How LLVM tools are used in graph compilers?
The intermediate representation is further divided into high level IRs and low-level IRs. The high level IRs are usually computation graphs of your ML models similar to tensorflow computation graph in TensorFlow 1.0, This high level IR are further optimized and tuned and then converted to low-level IRs. The low level IRs are used to generate machine-native code and compilers typically leverage a code generator, aka. codegen. The most popular codegen is LLVM, hence we lower the high-level framework code into low-level hardware-native code. 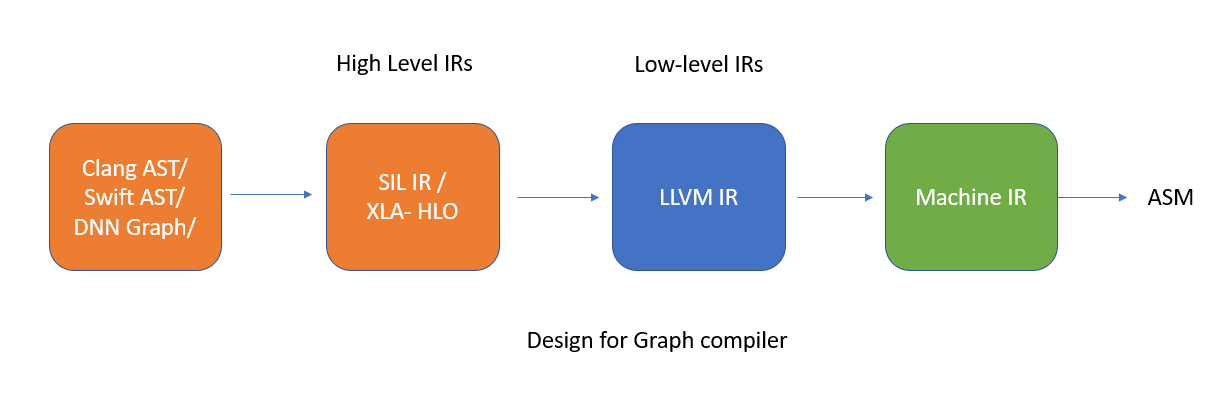
LLVMs have been used to add domain-specific extensions to an existing language. e.g. NVIDIA used LLVM to create Nvidia CUDA Compiler which lets languages add native support for CUDA that compiles as part of the native code. One of the big challenge LLVMs face is how domain-specific languages are hard to translate into LLVM IR without a lot of hard work on the front end.
One solution in the work is the Multi-Level Intermediate Representation, or MLIR project. MLIR provides convenient ways to represent complex data structures and operations, which can then be translated automatically into LLVM IR. e.g. Tensorflow ML framework could have many of its complex dataflow-graph operations efficiently compiled to native code with MLIR.